Bias In, Bias Out: How Healthcare Data Shapes AI
Artificial intelligence is increasingly embedded in clinical care. Algorithms now help predict sepsis, analyze imaging, and flag patients at risk for complications. These tools rely on large datasets drawn from electronic health records, medical imaging, and historical clinical outcomes.
The challenge is that these datasets reflect the healthcare systems that produced them. When inequities exist in care delivery, documentation, or research participation, those patterns appear in the data used to train algorithms. As a result, AI systems can reproduce or amplify existing health disparities.
Bias in healthcare AI often enters during the stages of data collection, labeling, model development, and evaluation. Understanding these forms of bias is essential for building systems that perform reliably across patient populations.
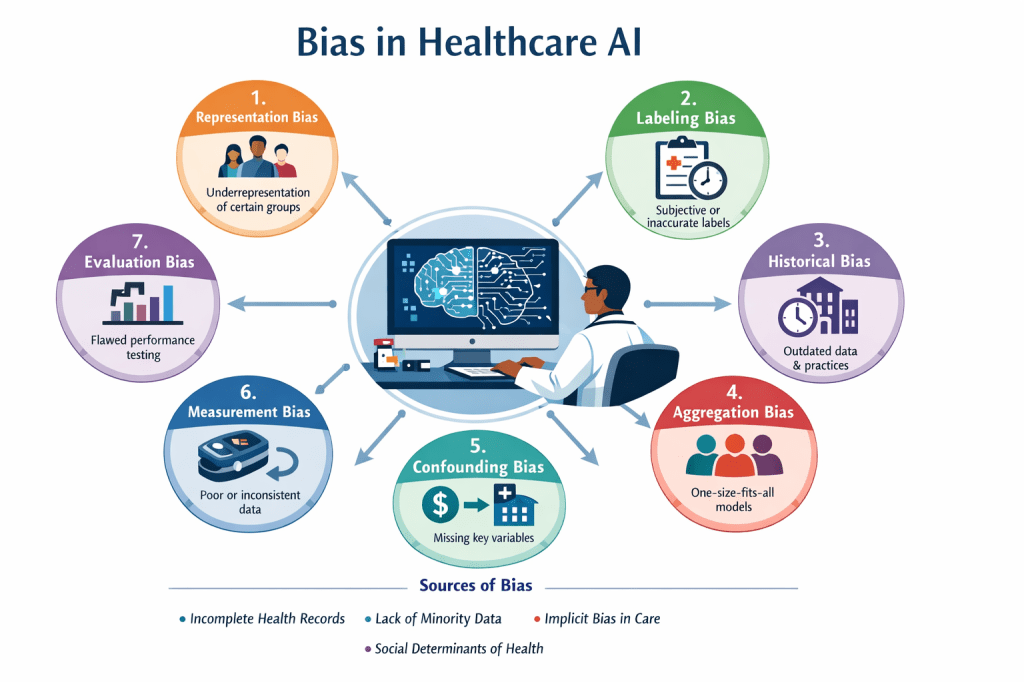
Representation Bias
(Underrepresentation or Sampling Bias)
Representation bias occurs when the training data does not reflect the diversity of the population where the model will be applied. When certain groups appear less frequently in the dataset, the algorithm has limited examples from which to learn.
Examples include:
- Cardiovascular prediction models developed primarily from male patient data, which may perform less accurately for women.
- Dermatology datasets used to train skin cancer detection algorithms have also been heavily weighted toward images of lighter skin tones, leading to reduced diagnostic accuracy in patients with darker skin.
This imbalance stems partly from longstanding patterns in medical research. Women, pregnant patients, racial minorities, older adults, and people with disabilities have historically been underrepresented in clinical trials and research datasets.
Labeling Bias
(Annotation or Measurement Bias)
Machine learning models depend on labeled data. If those labels are inconsistent, subjective, or influenced by bias, the algorithm may learn inaccurate patterns.
Clinical diagnoses and chart documentation often serve as labels for training datasets. When those labels reflect subjective judgments or historical disparities in care, the resulting dataset carries those patterns forward.
For example:
- If historical records consistently underestimate illness severity in certain patient groups, an algorithm trained on those records may replicate the same pattern.
- Subjective grading of tumor severity by pathologists can introduce variability into training datasets used for diagnostic models.
Historical Bias
(Temporal Bias)
Healthcare data reflects the clinical practices and social context of the period in which it was recorded. Models trained on large historical datasets may incorporate outdated treatment patterns, diagnostic criteria, or inequitable care practices.
For instance, an algorithm trained on decades of historical treatment data may learn patterns associated with past disparities in treatment allocation. Changes in clinical guidelines, diagnostic technology, and treatment standards can also affect how older data aligns with current practice.
Examples include:
- Body Mass Index – frequently used as a proxy for an individual’s overall health status, it is now widely recognized that the utilization of BMI is a source of medical bias, often failing to account for muscle mass, bone density, or metabolic health.
- GFR – historical race-based calculation was inaccurate, causing delays in treatment for Black patients, forcing the transition to a race-free formula to ensure equity.
Aggregation Bias
Aggregation bias occurs when a single model is applied across a heterogeneous population without accounting for subgroup differences. When diverse patient populations are combined into a single dataset and modeled as a uniform group, important variations may be lost.
An algorithm may perform well on average but demonstrate lower accuracy for specific populations. Patients with disabilities, rare conditions, or distinct physiological characteristics may not be adequately represented within a generalized model.
Confounding Bias
(Omitted Variable Bias)
Confounding bias arises when relevant variables are missing from the dataset. The model may detect correlations that appear meaningful but are actually driven by unmeasured factors.
A readmission prediction model might identify income level as associated with poor health outcomes. Without additional context, the model may attribute risk to income itself rather than to related factors such as lack of insurance, delayed care, or barriers to treatment.
Many healthcare datasets contain limited information about social determinants of health, including housing stability, transportation access, or environmental exposures. The absence of these variables can lead to misleading associations.
Measurement Bias
(Data Quality Bias)
Measurement bias occurs when data is collected with different levels of accuracy or completeness across patient groups.
Electronic health records may contain more missing information for patients who receive care across multiple healthcare systems or who face barriers to consistent access. Device accuracy can also vary across populations. Studies have demonstrated that pulse oximeters (SpO2) are not equally accurate for everyone; they can overestimate blood oxygen levels in people with darker skin, leading to potential delays in care. These devices are three times more likely to provide inaccurate readings for Black patients due to melanin interfering with light, creating significant racial bias – algorithms trained on this data to create clinical risk prediction and triage tools can produce inaccurate or harmful predictions/risk stratifications for dark skinned patients.
Differences in documentation practices, device performance, and healthcare access all contribute to variation in data quality.
Evaluation Bias
Evaluation bias occurs when models are assessed using metrics that mask differences in performance across subgroups.
A model might demonstrate high overall accuracy while performing substantially worse for smaller populations that were underrepresented in the testing dataset. When evaluation focuses only on aggregate results, these discrepancies may go undetected.
Structural Sources of Bias in Healthcare Data
Several structural factors contribute to bias in healthcare datasets:
- Incomplete or fragmented electronic health records
- Lower-quality care experienced by marginalized populations
- Limited datasets for minority groups
- Implicit bias in clinical decision-making
- Missing information about social determinants of health
Because AI models learn directly from these data sources, disparities present in the healthcare system can be reflected in algorithmic outputs.
Why This Matters for Clinical Practice
Clinical documentation contributes directly to the datasets used in healthcare AI development. Charted observations, diagnoses, and treatment decisions become part of the historical record used to train future models.
For clinicians, understanding how bias enters healthcare data provides context for evaluating new technologies and participating in discussions about algorithm design, data quality, and model evaluation.
Efforts to improve healthcare AI require attention not only to model development but also to the quality, diversity, and completeness of the data used to train these systems.
